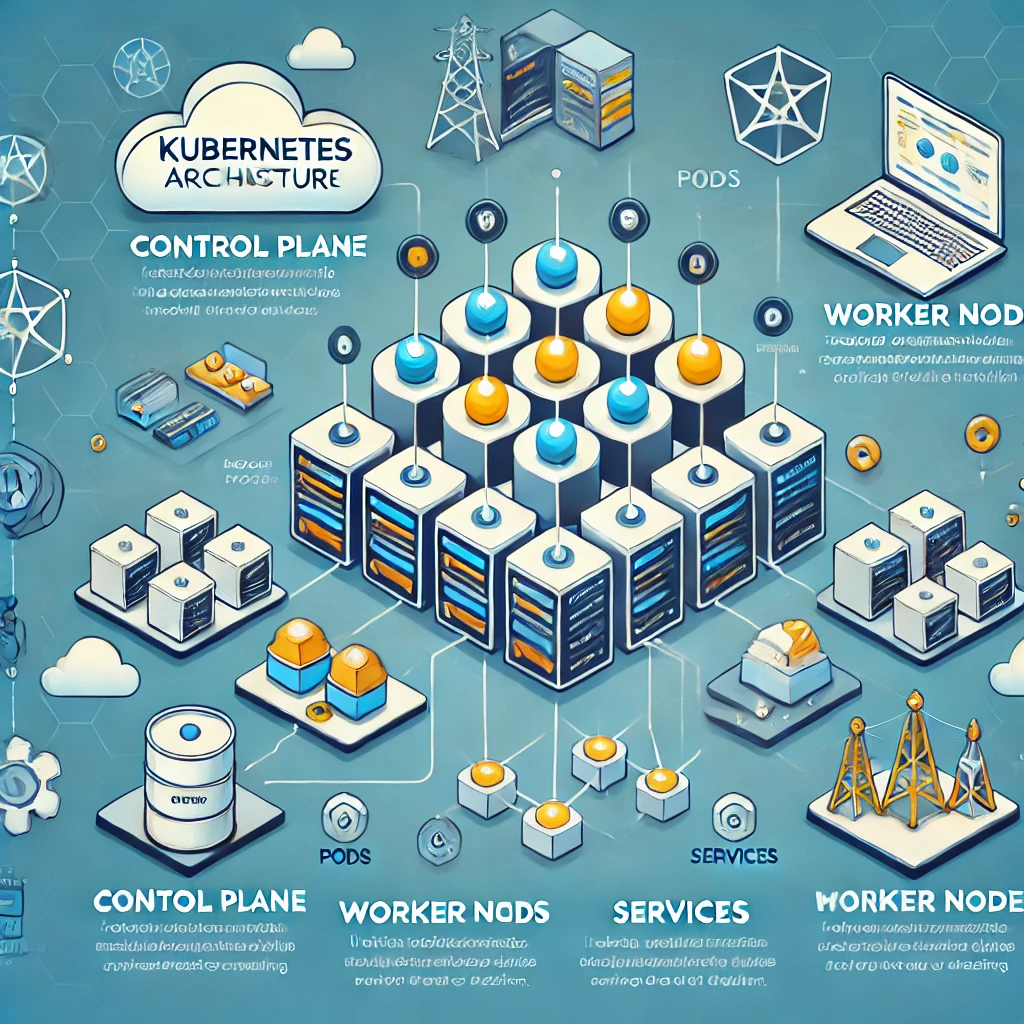

Have you ever tried to explain essential Kubernetes architecture to someone who’s never heard of it before? I have, and it’s not easy! Back when I first started exploring container orchestration after years of managing traditional servers, I felt like I was learning a new language.
Essentials Kubernetes architecture can seem overwhelming at first glance, especially for students and recent graduates preparing to enter the tech industry. But breaking down this powerful system into its core components makes it much more approachable.
In this post, I’ll walk you through the 8 essential elements of Kubernetes architecture that you need to know. Whether you’re preparing for interviews or gearing up for your first deployment, understanding these fundamentals will give you a solid foundation.
Understanding Kubernetes Architecture Fundamentals
Kubernetes architecture does one main thing – it automates how your containerized apps get deployed, scaled, and managed. Think of it as a smart system that handles all the heavy lifting of running your apps. After my B.Tech from Jadavpur University, I jumped into the world of product development where I quickly realized how container management was revolutionizing software delivery.
When I first started working with containers, I was using Docker directly. It was great for simple applications, but as our infrastructure grew more complex, managing dozens of containers across multiple environments became a nightmare. That’s when Kubernetes entered the picture for me.
At its core, Kubernetes follows a master/worker architecture pattern:
- Control Plane (Master): The brain that makes global decisions about the cluster
- Worker Nodes: The muscles that run your applications
This separation of responsibilities creates a system that’s both powerful and resilient. I’ve seen this architecture save the day many times when parts of our infrastructure failed but the applications kept running.
Control Plane Components: The Brain of Kubernetes
API Server: The Communication Hub
The API server works like a receptionist at a busy office. Everything and everyone must go through it first. Want to create a new app deployment? Talk to the API server. Need to check on your running apps? Ask the API server. It’s the front desk for all tasks in Kubernetes.
I remember one project where we were experiencing mysterious connection issues within our cluster. After hours of debugging, we discovered it was related to API server resource limits. We’d been too conservative with our resource allocation, causing the API server to become a bottleneck during peak loads.
The API server validates and processes RESTful requests, ultimately saving state to etcd. It acts as the gatekeeper, ensuring only authorized operations proceed.
etcd: The Cluster’s Brain
If the API server is the receptionist, etcd is the filing cabinet where all the important documents are stored. It’s a consistent and highly-available key-value store that maintains the state of your entire Kubernetes cluster.
Early in my container journey, I learned the hard way about the importance of etcd backups. During a cluster upgrade, we had an unexpected failure that corrupted our etcd data. Without a recent backup, we had to rebuild portions of our application configuration from scratch—a painful lesson!
For any production environment, I now always implement:
- Regular etcd backups
- High availability with at least 3 etcd nodes
- Separate disk volumes with good I/O performance for etcd
Scheduler: The Workload Placement Decision-Maker
The Scheduler is like the seating host at a restaurant, deciding which table (node) gets which customers (pods). It watches for newly created pods without an assigned node and selects the best node for them to run on.
The scheduling decision takes into account:
- Resource requirements
- Hardware/software constraints
- Affinity/anti-affinity specifications
- Data locality
- Workload interference
Once, we had an application that kept getting scheduled on nodes that would run out of resources. By adding more specific resource requests and limits, along with some node affinity rules, we guided the scheduler to make better decisions for our workload patterns.
Controller Manager: The Operations Overseer
The Controller Manager is like a team of supervisors watching over different parts of your cluster. Each controller has one job – to make sure things are running exactly how you wanted them to run. If something’s not right, these controllers fix it automatically.
Some key controllers include:
- Node Controller: Notices and responds when nodes go down
- Replication Controller: Maintains the correct number of pods
- Endpoints Controller: Populates the Endpoints object
- Service Account & Token Controllers: Create accounts and API access tokens
I’ve found that understanding these controllers is crucial when troubleshooting cluster issues. For example, when nodes in our development cluster kept showing as “NotReady,” investigating the node controller logs helped us identify networking issues between our control plane and worker nodes.
Key Takeaway: The control plane components work together to maintain your desired state. Think of them as the management team that makes sure everything runs smoothly without your constant attention.
Worker Node Components: The Muscle of Kubernetes
Kubelet: The Node Agent
Kubelet is like the manager at each worker node, making sure containers are running in a Pod. It takes a set of PodSpecs provided by the API server and ensures the containers described are running and healthy.
When I was first learning Kubernetes, I found Kubelet logs to be my best friend for debugging container startup issues. They show exactly what’s happening during container creation and can reveal problems with image pulling, volume mounting, or container initialization.
A typical issue I’ve faced is when Kubelet can’t pull container images due to registry authentication problems. Checking the Kubelet logs will quickly point to this issue with messages about failed pull attempts.
Kube-proxy: The Network Facilitator
Kube-proxy maintains network rules on each node, allowing network communication to your Pods from inside or outside the cluster. It’s the component that makes Services actually work.
In one project, we were using a service to access a database, but connections were periodically failing. The issue turned out to be kube-proxy’s default timeout settings, which were too aggressive for our database connections. Adjusting these settings resolved our intermittent connection problems.
Kube-proxy operates in several modes:
- IPTABLES (default): Uses Linux iptables rules
- IPVS: For higher performance and more load balancing algorithms
- Userspace (legacy): An older, less efficient mode
Container Runtime: The Execution Engine
The container runtime is the software that actually runs your containers. It’s like the engine in a car – you don’t interact with it directly, but nothing works without it. While Docker might be the most well-known container runtime, Kubernetes supports several options:
- containerd
- CRI-O
- Docker Engine (via dockershim, though this is being phased out)
When I first started with Kubernetes, Docker was the default runtime. But as the ecosystem matured, I’ve migrated clusters to containerd for better performance and more direct integration with Kubernetes.
The container runtime handles:
- Pulling images from registries
- Starting and stopping containers
- Mounting volumes
- Managing container networking
Key Takeaway: Worker node components do the actual work of running your applications. They follow instructions from the control plane but operate independently, which makes Kubernetes resilient to failures.
Add-ons and Tools: Extending Functionality
While the core components provide the foundation, add-ons extend Kubernetes functionality in critical ways:
| Add-on Type | Popular Options | Function |
|---|---|---|
| Networking | Calico, Flannel, Cilium | Pod-to-pod networking and network policies |
| Storage | Rook, Longhorn, CSI drivers | Persistent storage management |
| Monitoring | Prometheus, Grafana, Datadog | Metrics collection and visualization |
| Logging | Elasticsearch, Fluentd, Loki | Log aggregation and analysis |
I’ve learned that picking the right add-ons can make or break your Kubernetes experience. During one project, my team needed strict network security rules between services. We chose Calico instead of simpler options like Flannel, which made a huge difference in how easily we could control traffic between our apps.
Kubernetes Architecture in Action: A Simple Example
Let’s see how all these components work together with a simple example. Imagine you’re deploying a basic web application that consists of a frontend and a backend service.
Here’s what happens when you deploy this application:
- You submit a deployment manifest to the API Server
- The API Server validates the request and stores it in etcd
- The Deployment Controller notices the new deployment and creates a ReplicaSet
- The ReplicaSet Controller creates Pod objects
- The Scheduler assigns each Pod to a Node
- The Kubelet on that Node sees the Pod assignment
- Kubelet tells the Container Runtime to pull and run the container images
- Kube-proxy updates network rules to make the Pods accessible
This whole process typically takes just seconds. And the best part? Once it’s running, Kubernetes keeps monitoring everything. If a pod crashes or a node fails, Kubernetes automatically reschedules the workloads to maintain your desired state.
While working on an e-commerce platform, we needed to handle high-traffic events like flash sales. Understanding how these components interact helped us design an architecture that could dynamically scale based on traffic patterns. We set up Horizontal Pod Autoscalers linked to Prometheus metrics so our platform could automatically expand capacity during traffic spikes.
One interesting approach I’ve implemented is running different workload types on dedicated node pools. For instance, stateless API services on one node pool and database workloads on nodes with SSD-backed storage. This separation helps optimize resource usage and performance while letting the scheduler make appropriate placement decisions.
Common Challenges for Kubernetes Newcomers
When you’re just starting with Kubernetes, you’ll likely face some common hurdles:
- Configuration complexity: YAML files can be finicky, and a small indentation error can break everything
- Networking concepts: Understanding services, ingress, and network policies takes time
- Resource management: Setting appropriate CPU/memory limits is more art than science at first
- Troubleshooting skills: Knowing which logs to check and how to diagnose issues comes with experience
I remember spending hours debugging my first deployment only to find I had used the wrong port number in my service definition. These experiences are frustrating but incredibly valuable for learning how Kubernetes actually works.
Kubernetes Knowledge and Your Career
If you’re aiming for a job in cloud engineering, DevOps, or even modern software development, understanding Kubernetes architecture will give you a major advantage in interviews and real-world projects. Several entry-level roles where Kubernetes knowledge is valuable include:
- Junior DevOps Engineer
- Cloud Support Engineer
- Site Reliability Engineer (SRE)
- Platform Engineer
- Backend Developer (especially in microservices environments)
Companies increasingly run their applications on Kubernetes, making this knowledge transferable across industries and organizations. I’ve seen recent graduates who understand containers and Kubernetes fundamentals get hired faster than those with only traditional infrastructure experience.
FAQ Section
What are the main components of Kubernetes architecture?
Kubernetes architecture consists of two main parts:
- Control Plane components: API Server, etcd, Scheduler, and Controller Manager
- Worker Node components: Kubelet, Kube-proxy, and Container Runtime
Each component has a specific job, and they work together to create a resilient system for running containerized applications. The control plane components make global decisions about the cluster, while the worker node components run your actual application workloads.
How does Kubernetes manage containers?
Kubernetes doesn’t directly manage containers—it manages Pods, which are groups of containers that are deployed together on the same host. The container lifecycle is handled through several steps:
- You define the desired state in a YAML file (like a Deployment)
- Kubernetes Control Plane schedules these Pods to worker nodes
- Kubelet ensures containers start and stay running
- Container Runtime pulls images and runs the actual containers
For example, when deploying a web application, you might specify that you want 3 replicas. Kubernetes will ensure that 3 Pods are running your application containers, even if nodes fail or containers crash.
What’s the difference between control plane and worker nodes?
I like to think of this as similar to a restaurant. The control plane is like the management team (the chef, manager, host) who decide what happens and when. The worker nodes are like the kitchen staff who actually prepare and serve the food.
Control plane nodes make global decisions about the cluster (scheduling, detecting failures, etc.) while worker nodes run your actual application workloads. In production environments, you’ll typically have multiple control plane nodes for high availability and many worker nodes to distribute your workloads.
Is Kubernetes architecture cloud-provider specific?
No, and that’s one of its greatest strengths! Kubernetes is designed to be cloud-provider agnostic. You can run Kubernetes on:
- Public clouds (AWS, GCP, Azure)
- Private clouds (OpenStack, VMware)
- Bare metal servers
- Even on your laptop for development
While working on different products, I’ve deployed Kubernetes across multiple cloud environments. The core architecture remains the same, though some implementation details like storage and load balancer integration will differ based on the underlying platform.
How does Essential Kubernetes architecture handle scaling?
Kubernetes offers multiple scaling mechanisms:
- Horizontal Pod Autoscaling: Automatically increases or decreases the number of Pods based on CPU utilization or custom metrics
- Vertical Pod Autoscaling: Adjusts the CPU and memory resources allocated to Pods
- Cluster Autoscaling: Automatically adds or removes nodes based on pending Pods
In a recent project, we implemented horizontal autoscaling based on queue length metrics from RabbitMQ. When message queues grew beyond a certain threshold, Kubernetes automatically scaled up our processing Pods to handle the increased load, then scaled them back down when the queues emptied.
What happens when a worker node fails?
When a worker node fails, Kubernetes automatically detects the failure through the Node Controller, which monitors node health. Here’s what happens next:
- The Node Controller marks the node as “NotReady”
- If the node remains unreachable beyond a timeout period, Pods on that node are marked for deletion
- The Controller Manager creates replacement Pods
- The Scheduler assigns these new Pods to healthy nodes
I’ve experienced node failures in production, and the self-healing nature of Kubernetes is impressive to watch. Within minutes, all our critical services were running again on other nodes, with minimal impact to users.
Kubernetes Architecture: The Big Picture
Understanding Kubernetes architecture is essential for anyone looking to work with modern cloud applications. The 8 essential elements we’ve covered form the backbone of any Kubernetes deployment:
- API Server
- etcd
- Scheduler
- Controller Manager
- Kubelet
- Kube-proxy
- Container Runtime
- Add-ons and Tools
While the learning curve may seem steep at first, focusing on these core components one at a time makes the journey manageable. My experience across multiple products and domains has shown me that Kubernetes knowledge is highly transferable and increasingly valued in the job market.
As container orchestration continues to evolve, Kubernetes remains the dominant platform with a growing ecosystem. Starting with a solid understanding of its architecture will give you a strong foundation for roles in cloud engineering, DevOps, and modern application development.
Ready to continue your Kubernetes journey? Check out our Interview Questions page to prepare for technical interviews, or dive deeper with our Learn from Video Lectures platform where we cover advanced Kubernetes topics and hands-on exercises that will help you master these concepts.
What aspect of Kubernetes architecture are you most interested in learning more about? Share your thoughts in the comments below!